YOLOv3 on the Xilinx Kria KV260 AI Vision Starter Kit
Real-Time Object Detection on the Xilinx Kria
YOLOv3 is a convolutional neural network used in this project to perform real-time object detection. YOLOv3 works by taking a single image, dividing it into multiple areas and predicting bounding boxes and probabilities for each region. These bounding boxes are then weighted by their predicted probabilities. The result of this operation is image ratios used to calculate the resolution for the bounding boxes, together with the appropriate class id number.
For some of our previous work using YOLO v3 on the Zynq UltraScale+ MPSoC ZCU104 you can click here.
Ivica Matić
Kria KV260 Vision AI Starter Kit
The Kria KV260 is a development board made by XIlinx featuring Zynq® UltraScale+™ MPSoC FPA device on board. It comes in a SOM + Carrier Board form factor with relatively low cost and size, providing the user-friendly platform for accelerating Vision applications using XIlinx hardware, products and toolchains.
KV260 Vision AI Starter Kit board is followed and supported by Vitis AI software, which provides an easy way for developers to adapt their AI models to work on an FPGA architecture.
In our work, we are primarily using YoloV3 real-time object detection neural network/ system to train our network to recognize objects required depending on our project goal and needs.
Workflow to train a custom Yolov3 neural network consists of:
- Obtain the images for training the neural network
- Annotate the objects on the image using our annotation tool
- Move the images to the AWS instance
- Move the annotation files to the AWS instance
- Run the training command
- Download trained weights from AWS instance and run the inference for evaluation
- Convert darknet yolov3 weights to TensorFlow files
- Quantize and compile the neural network using Vitis AI Tool
- Run the inference on FPGA target device
For this demo and evaluation purposes, we trained our neural network on COCO dataset.
You can download the pre-trained network on https://pjreddie.com/darknet/yolo/
As GPU devices work quite well with floating-point numbers, unlike FPGAs, we need to convert our neural network model to use integer numbers. This task is accomplished using the Vitis AI tool. But because VAI does not natively support Darknet Yolov3 we need to convert it to a TensorFlow model using a conversion tool that can be found here.
Afterwards, we can continue to quantize our model by providing a subset of original un-labelled images used for training at the first stage when we used our AWS darknet container.
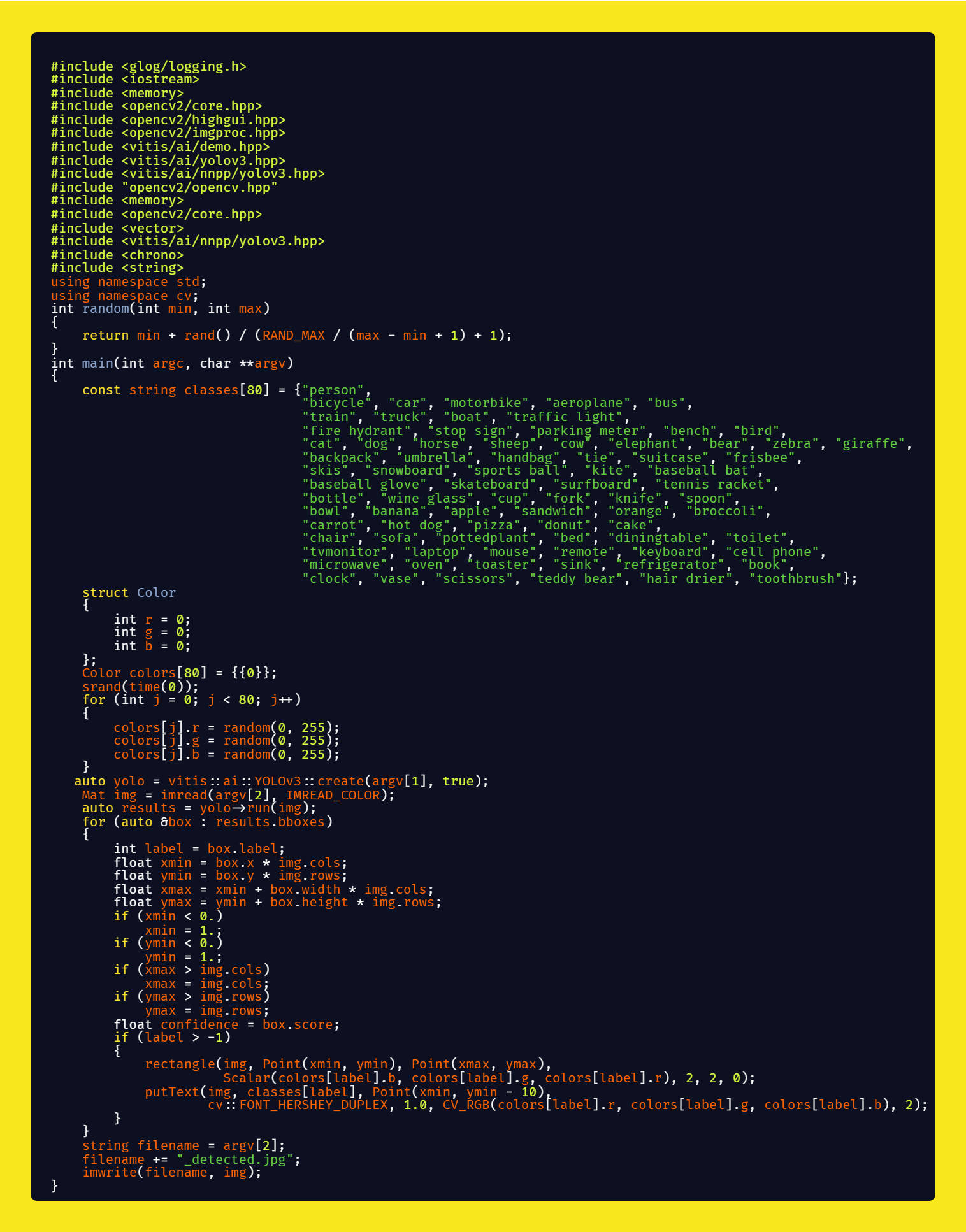
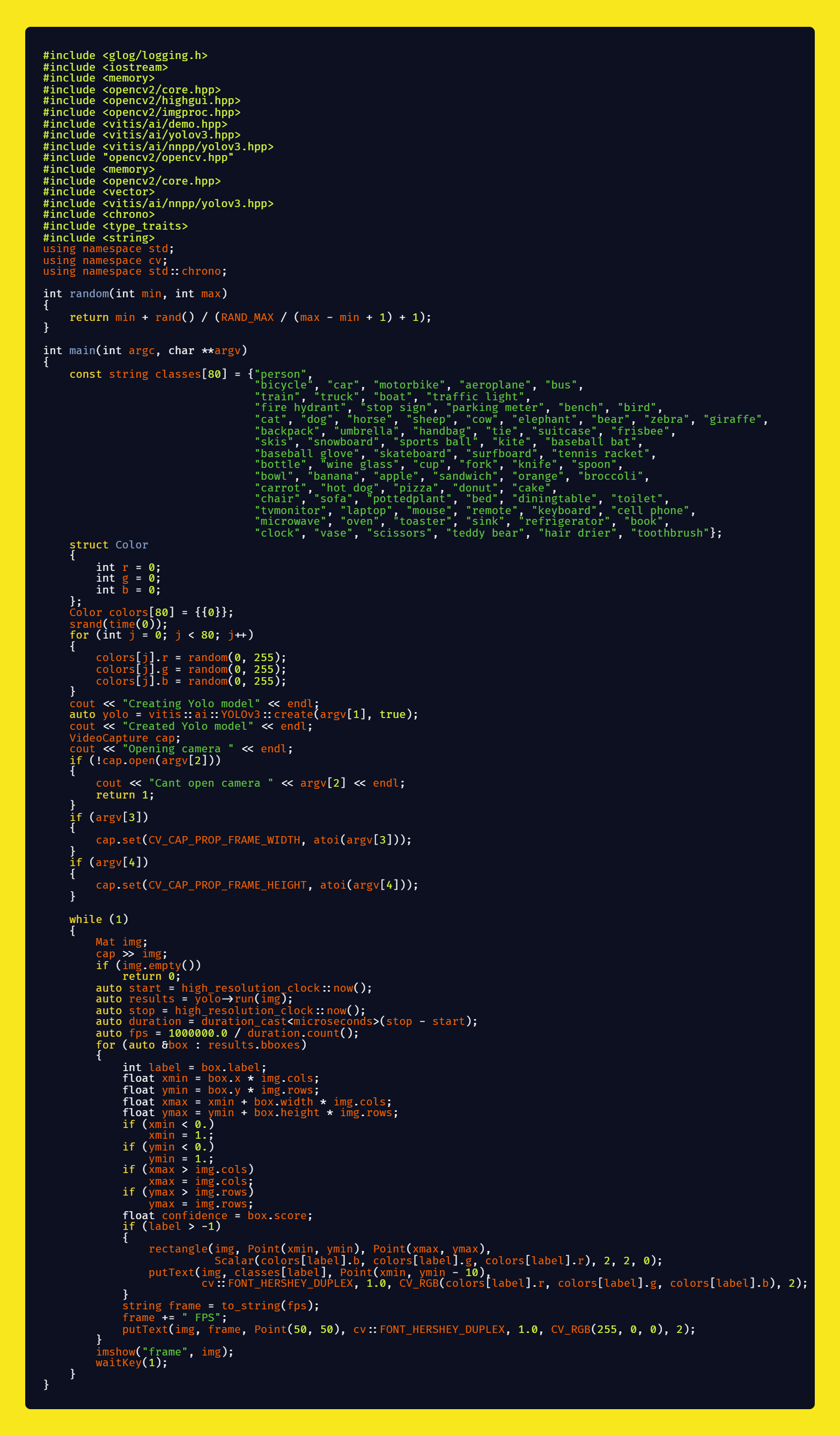
Then you can run the code using:
For inference on image: ./custom_yolov3_image ./yolov3coco selfie.jpg
For inference on video file: ./custom_yolov3_video ./yolov3coco testvid_480p.webm 640 480
For inference on webcam: ./custom_yolov3_video ./yolov3coco /dev/video0 640 480